
Hasura this week extended its data delivery platform to make it easier to invoke metadata that can be exposed to application programming interfaces (APIs) at a more granular level.
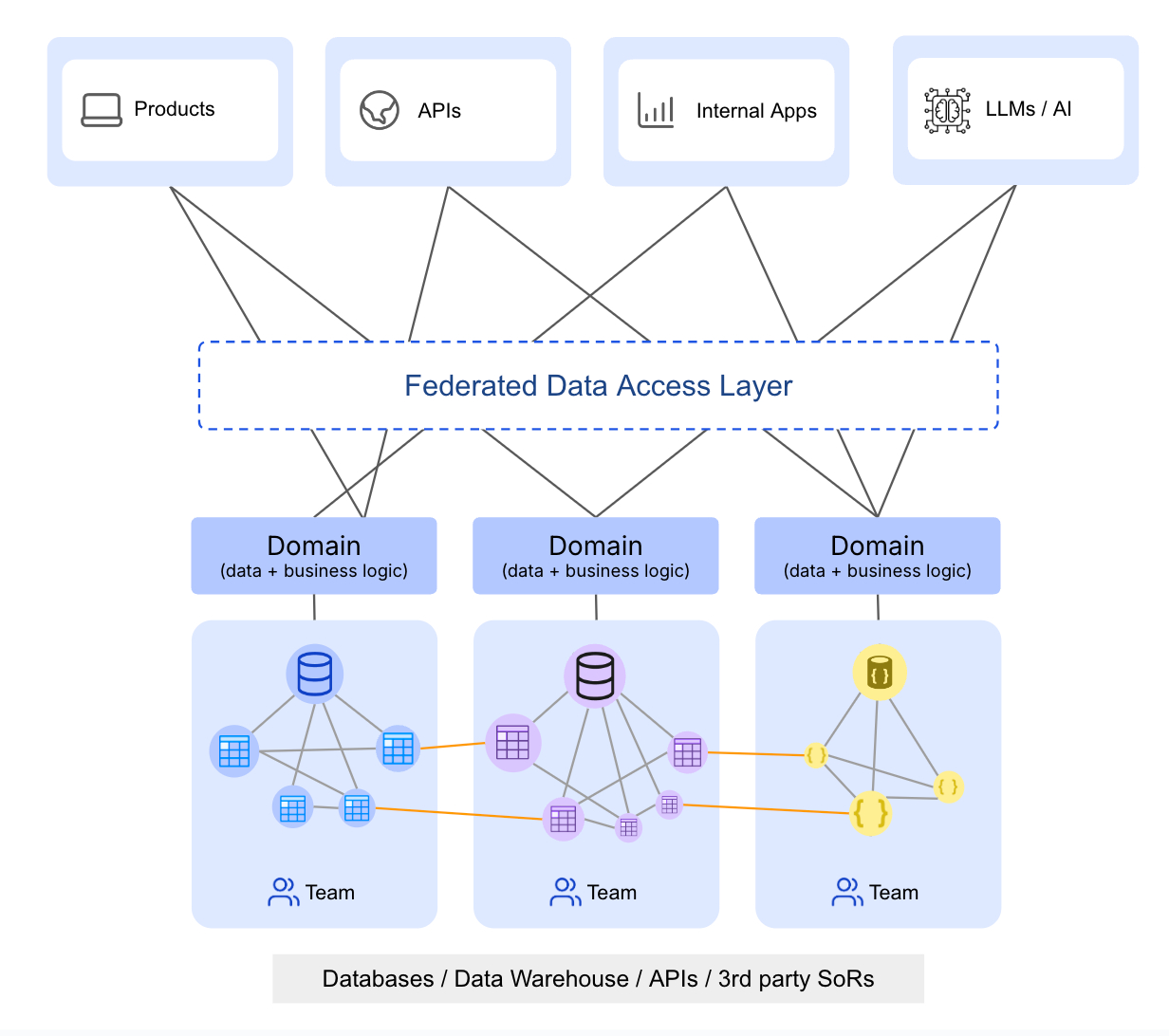
The Hasura Data Delivery Network (DDN) captures metadata in a way that makes it possible to create a “supergraph” to centrally manage workflows across a distributed computing environment. Based on an open specification, the Hasura DDN declaratively models the domain, entities, relationships and permissions to create a semantic graph that can then be invoked via multiple types of APIs. That supergraph then enables the underlying Hasura engine to compile incoming API requests into queries that can be executed against upstream data sources in a way that can be centrally governed.
The Hasura DDN is now being extended to make it possible to capture more modular sets of metadata that can now also be used across workflows spanning multiple federated teams that are working in different domains. That approach gives teams the option to manage and iterate on just their own metadata residing in a separate repository. Earlier versions of Hasura DDN required multiple teams to manage metadata from a single repository.
The company has also added a schema registry to, for example, compare metadata builds and better understand their potential downstream impact. A changelog that has also been added makes it simpler to track updates to builds.
Each metadata build is instantly validated by the supergraph to flag any potential conflicts early and reducing wasted development cycles. In addition, Hasura DDN provides access to instant preview along with rollback capabilities.
A decentralized authorization system added with this update enables developers to evolve their metadata, create domain-level builds, and combine those builds with others to preview different supergraph versions. However, only domain administrators can apply changes to the production supergraph.
Hasura CEO Tanmai Gopal said that capability will make it easier for IT organizations to, for example, introspect the data they might expose to a large language model (LLM). “Organizations need to be able to discover the relationships between their data,” he says.
In general, Hasura is making a case for programmatically managing workflows at a higher level of semantic abstraction using metadata exposed by APIs that are at the heart of any modern workflow process. Graph technology is already starting to be more widely employed to manage data, but Hasura is applying that concept at a level of scale that makes it simpler for organizations to create and alter workflows as needed.
That’s critical in an era where organizations are attempting to impose order on workflows that depend on APIs being able to serve up the right data at the right time, noted Gopal.
It’s not clear how quickly organizations are embracing graph technologies to manage data workflows, but as IT continues to evolve, it is becoming simpler to maintain relationships between data sets even as they are continuously updated. The challenge and the opportunity now is determining what level of IT expertise is going to be needed to make that transition.
Techstrong TV
Digital CxO Podcast
Digital CxO Webinars
